Back of the Book Indexes using XSL-FO 1.0
Introduction
This describes a fully unattended batch methodology for producing "back of the book indexes" using XSL-FO 1.0 and a free tool available on the Web. We hope that other free tools can be identified for use in this process, and we will maintain this page with the list as they are found.
Certainly such functionality will be available in a future version of XSL-FO, but this methodology can help users of XSL-FO 1.0.
One might think after a quick read of XSL-FO that indexing is implicitly supported, but this turns out not to be the case. Generating tables of content is very straightforward, because each table of content entry has a single page number citation. There is no need to do arbitration between multiple page number citations for a single entry.
This need for arbitrating page number citations is the problem with supporting a back of the book index in XSL-FO. The transformation process does not know where the page breaks will occur in the formatting process. If a particular index entry is cited a number of times on a single page, it is unsightly to have the page number repeated in the rendering. It is also common to have citations found on each of a sequence of pages rationalized into a range.
Moreover, there is no single algorithm for massaging a collection of page number citations into solitary page numbers, page ranges or a combination of the two that might overlap. Perhaps a particular citation should be in bold font to reflect some semantic of why the page number is being cited, and that it should not participating in range reduction. There may be other reasons specific to the book why particular citations should not participate in range reduction or should be rendered with specialized formatting.
For these reasons, it will be a challenge to standardize a particular implementation of an index accepted by all users or utilized to produce all kinds of indexes needed.
This methodology describes an unattended batch approach that puts the massaging of index entries into the hands of the user of XSL-FO such that a fully customized index can be rendered on an arbitrary document. This is a proven methodology and has been put in place for Crane's next publishing cycle of its electronic books.
The methodology
This is a two-pass methodology, determining during the first pass what the index information is to be added, and then reproducing the original results with the index information as an addition input to the formatting transformation. The same stylesheet is used for both passes, with the different behaviors triggered by the absence or presence of the filename for an XML expression of the index information.
The following diagram summarizes the flow of information in this methodology:
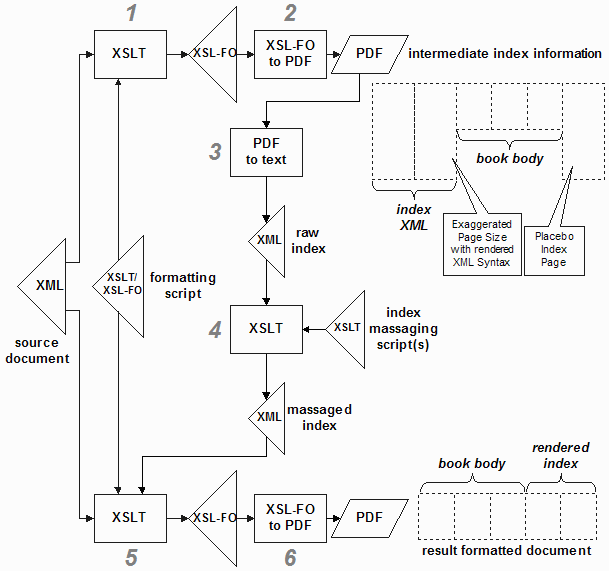
Step 1 - Produce index instance in FO
This runs the original document through the first pass, prefixing the formulated body pages with extractable index information and page number citations.
The extractable index is rendered as composed markup, exposing the angle brackets and all aspects of XML markup onto the canvas. The demonstration places page number citations between the attribute quotes such that the composed version of the page will have decimal page numbers in the attributes.
For example, the following FO:
<inline keep-together="always"><p </inline>
<inline keep-together="always">s="<page-number-citation
ref-id="d0e16"/>"/></inline>
uses inline keeps in order to ensure the line breaks will not disturb the well-formed XML syntax and will render the following on the canvas:
<p s="17"/>
which can then be extracted by a tool that reads the PDF file and writes out simple text. The stylesheet writer can make this markup as simple or as complex as desired in order to implement any desired semantics for normalizing page ranges or perhaps highlighting particular page entries.
Note the first page sequence of the body must have an explicit initial-page-number="1" property otherwise the prefix of the two index pages would skew the proper page number of the body since the final result doesn't have this prefix. Since this page number is odd, the extractable index will always take up an even number of pages. The demonstration assumes the index information, when composed, will fit in less than two pages.
Note that Crane's flow happens to put a dummy page at the end where the index belongs, so that page number citations in the body to the first index page are resolved in the first pass with the correct page number.
Step 2 - Produce PDF from FO
This runs the XSL-FO engine, creating the PDF page images and resolving the page number citations found in the exposed XML. The resulting attribute values displayed on the canvas have true page numbers.
Note the page dimensions used are exaggerated for two reasons
-
the more real-estate that is available, the more index information will fit on the two prefix pages (any information on a third page would be lost in the next step)
-
a page with an exaggerated size would not be mistakenly used in a production environment
The Crane stylesheets use an exaggerated page length of 200 inches and a page width of 50 inches to get a lot of real estate to work with.
Step 3 - Extract XML instance from PDF
The index information is at the beginning of the document because the length of the document is unknown and the tool being used cannot address the end of the document.
The free pdftotext tool is part of the Xpdf package version 2.01 from http://www.foolabs.com/xpdf/. This tool extracts as many pages as requested into a simple text file, and follows each page with a form-feed (hex 0C) character. In this case, it is assumed all the information will be on the first two pages (the ones with the exaggerated page sizes). We also found the use of the Courier font produced the most consistent results with this tool. Note the use of arguments in this example:
pdftotext -f 1 -l 2 -layout file.pdf file.txt
invokes the process for only the first two pages (first=1 and last=2) and engages a mode of operation that produces clean text for large files.
An egrep pass removes all lines that contain form-feeds, changing the extracted text into a well-formed XML file.
We welcome any suggestions for alternative tools to extract the text of a PDF file as a simple text file, and will maintain the list in the section below.
Step 4 - Massage index information
This converts the raw collection of index information into that subset to be rendered. Duplicate page numbers are removed and sequential page numbers are changed into a range. Crane's stylesheets also distinguish important page citations, such as term definitions, and protect these from being subsumed by a range.
Step 5 - Produce final instance in FO
This reformats the entire document, but doesn't add the prefix because of the presence of an XML file of massaged index information. The index information from the external file is formatted just as if it had been authored or found as a part of the main body of XML. Crane's stylesheets introduce hyperlinks from the index entries to the pages on which the indexed items are found (this is not part of this simple demo).
Step 6 - Produce PDF from FO
The final instance is formatted and there are no pages with exaggerated sizes.
The demo
The latest package of demonstration files is: bbi-20021213-0250.zip
The demonstration files include all input, temporary and output files in a sample run of the methodology. The files in the demo are as follows:
-
doc.bat choreographs the process
-
doc.xml is the source document to be published
-
doc.xsl is the stylesheet
-
doc-index.xsl prepares the index information
-
doc.pdf is the final output
-
temp-raw.fo is the first pass XSL-FO output with the raw index information
-
temp-raw.pdf is the formatted result of the raw index information
-
temp-raw-index.txt is the raw index information as a text file
-
temp-raw-index.xml is the raw index information as an XML file
-
temp-index.xml is the massaged index information
-
temp.fo is the second pass XSL-FO with the complete index information
The following is the choreography of the process in the demonstration, expressed as an MSDOS batch file:
rem Step 0 - clean up environment if exist doc.pdf del doc.pdf if exist temp-*.* del temp-*.* rem Step 1 - produce index instance in FO call xslt doc.xml doc.xsl temp-raw.fo rem Step 2 - produce PDF from FO call xslfo temp-raw.fo temp-raw.pdf rem Step 3 - extract XML instance from PDF call pdftotext -f 1 -l 2 -layout temp-raw.pdf temp-raw-index.txt egrep -v ^L temp-raw-index.txt >temp-raw-index.xml rem Step 4 - massage index information call xslt temp-raw-index.xml doc-index.xsl temp-index.xml rem Step 5 - produce final instance in FO call xslt doc.xml doc.xsl temp.fo "index-file=temp-index.xml" rem Step 6 - produce PDF from FO call xslfo temp.fo doc.pdf rem Done
Available page extraction tools
The following tools have been identified as successfully extracting a particular number of pages of composed text from the output of an XSL-FO processor:
-
pdftotext in Xpdf Version 2.01 from http://www.foolabs.com/xpdf/
Please help us build up this list if you can.

SOFTWRIGHTS
LTD.
